
 闂佽壈椴告穱娲敊閿燂拷
闂佽壈椴告穱娲敊閿燂拷 AI闁诲繐绻愮换妤佺閿燂拷 闂佺厧鐤囧Λ鍕疮閹炬潙顕辨慨妯块哺閺嗭拷
AI闁诲繐绻愮换妤佺閿燂拷 闂佺厧鐤囧Λ鍕疮閹炬潙顕辨慨妯块哺閺嗭拷 闂佺硶鏅濋崰搴ㄥ箖閿燂拷
闂佺硶鏅濋崰搴ㄥ箖閿燂拷基于curl数据采集之单页面采集函数get_html的使用_PHP教程
缂傚倷绀佸ú锕傚焻缁€鎱筪eCMS闁荤喐鐟ュΛ婵嬨€傞崼鏇炴瀬婵炲棙鍨熼弻锟�婵炴垶姊规竟鍡涘煘閺嶎厽鈷掗柨鐕傛嫹 缂備礁顦遍崰鎰耿閸ヮ剙绀夐柍銉ㄦ珪閻濓拷 闂備緡鍋勯ˇ杈╃礊婢跺本鍏滈柡鍥ㄦ皑闂夊秹鏌ゆ潏銊︻棖缂佹唻鎷� 闂佸搫鍟版慨鎾椽閺嶎偆鍗氭繛鍡樻尰濮f劗鈧鎮堕崕閬嶅矗閿燂拷,闂佽皫鍕姢閻庤濞婂鍫曞礃椤斿吋顏熸繛鎴炴尨閸嬫捇姊哄▎鎯ф灈闁告瑥绻樺濠氭晸閿燂拷!
推荐:基于curl数据采集之正则处理函数get_matches的使用
本篇文章介绍了,基于curl数据采集之正则处理函数get_matches的使用。需要的朋友参考下
这是一个系列 没办法在一两天写完 所以一篇一篇的发布
大致大纲:
2.curl数据采集系列之多页面并行采集函数get_htmls
3.curl数据采集系列之正则处理函数get _matches
4.curl数据采集系列之代码分离
5.curl数据采集系列之并行逻辑控制函数web_spider
单页面采集在数据采集过程中是最常用的一个功能 有时在服务器访问限制的情况下 只能使用这种采集方式 慢 但是可以简单的控制 所以写好一个常用的curl函数调用是很重要的
百度和网易比较熟悉 所以拿这两个网站首页采集来做例子讲解
最简单的写法:
复制代码 代码如下:www.mb5u.com
$url = 'http://www.baidu.com';
$ch = curl_init($url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
curl_setopt($ch,CURLOPT_TIMEOUT,5);
$html = curl_exec($ch);
if($html !== false){
echo $html;
}
由于使用频繁 可以利用curl_setopt_array写成函数的形式:
复制代码 代码如下:www.mb5u.com
function get_html($url,$options = array()){
$options[CURLOPT_RETURNTRANSFER] = true;
$options[CURLOPT_TIMEOUT] = 5;
$ch = curl_init($url);
curl_setopt_array($ch,$options);
$html = curl_exec($ch);
curl_close($ch);
if($html === false){
return false;
}
return $html;
}
复制代码 代码如下:www.mb5u.com
$url = 'http://www.baidu.com';
echo get_html($url);
有时候需要传递一些特定的参数才能得到正确的页面 如现在要得到网易的页面:
复制代码 代码如下:www.mb5u.com
$url = 'http://www.163.com';
echo get_html($url);
会看到一片空白 什么也没有 那么再利用curl_getinfo写一个函数 看看发生了什么:
复制代码 代码如下:www.mb5u.com
function get_info($url,$options = array()){
$options[CURLOPT_RETURNTRANSFER] = true;
$options[CURLOPT_TIMEOUT] = 5;
$ch = curl_init($url);
curl_setopt_array($ch,$options);
$html = curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
return $info;
}
$url = 'http://www.163.com';
var_dump(get_info($url));

可以看到http_code 302 重定向了 这时候就需要传递一些参数了:
复制代码 代码如下:www.mb5u.com
$url = 'http://www.163.com';
$options[CURLOPT_FOLLOWLOCATION] = true;
echo get_html($url,$options);
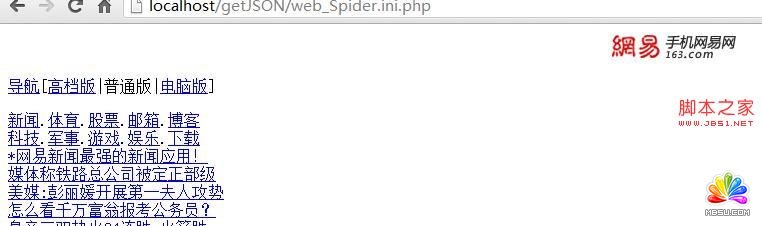
会发现 怎么是这样的一个页面 和我们电脑访问的不同???
看来参数还是不够 不够服务器判断我们的客户端是什么设备上的 就返回了个普通版
看来还要传送USERAGENT
复制代码 代码如下:www.mb5u.com
$url = 'http://www.163.com';
$options[CURLOPT_FOLLOWLOCATION] = true;
$options[CURLOPT_USERAGENT] = 'Mozilla/5.0 (Windows NT 6.1; rv:19.0) Gecko/20100101 Firefox/19.0';
echo get_html($url,$options);
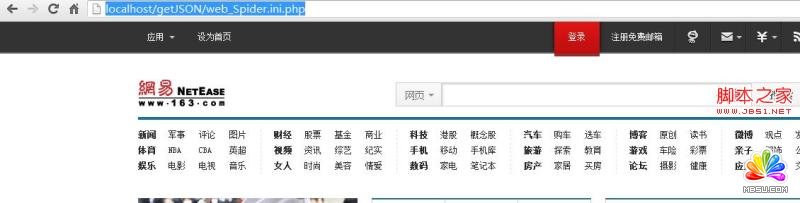
OK现在页面已经出来了 这样基本这个get_html函数基本能实现这样扩展的功能
当然也有另外的办法可以实现,当你明确的知道网易的网页的时候就可以简单采集了:
复制代码 代码如下:www.mb5u.com
$url = 'http://www.163.com/index.html';
echo get_html($url);
这样也可以正常的采集
分享:基于curl数据采集之单页面并行采集函数get_htmls的使用
用第一篇的get_html()实现简单的数据采集,由于是一个一个执行才采集数据的传输时间就会是所有页面下载的总时长,一个页面假设1秒,那么10个页面就是10秒了。所幸curl还提供了并行处理的功能
 评论加载中....
评论加载中....相关PHP教程:
- 相关链接:
- 教程说明:
PHP教程-基于curl数据采集之单页面采集函数get_html的使用
 。
。