
 AI闂備浇顕х换鎰崲閹邦喗宕叉俊銈勮兌椤╃兘鏌ㄩ悤鍌涘 闂傚倷鑳堕崢褔鎮块崶顬盯宕熼姘辨焾闂佸湱鍋撳ḿ娆擃敋鏉堛劍鍙忔俊顖氭健閸濇椽鏌¢崱顓熷
AI闂備浇顕х换鎰崲閹邦喗宕叉俊銈勮兌椤╃兘鏌ㄩ悤鍌涘 闂傚倷鑳堕崢褔鎮块崶顬盯宕熼姘辨焾闂佸湱鍋撳ḿ娆擃敋鏉堛劍鍙忔俊顖氭健閸濇椽鏌¢崱顓熷
 闂傚倷鑳剁涵鍫曞疾濠靛绐楅幖娣妼缁犳牠鏌ㄩ悤鍌涘
闂傚倷鑳剁涵鍫曞疾濠靛绐楅幖娣妼缁犳牠鏌ㄩ悤鍌涘
 闂傚倷娴囬~澶嬬娴犲绀夐煫鍥ㄦ尵閺嗭箓鏌ㄩ悤鍌涘
闂傚倷娴囬~澶嬬娴犲绀夐煫鍥ㄦ尵閺嗭箓鏌ㄩ悤鍌涘
SupeSite 7.0 采集管理-添加新机器人说明教程_SupeSite教程
初次接触 SupeSite 的采集器,可能会感觉难以上手,本文将带你熟悉 SupeSite 的采集器,让您根据自己的情况做出自己的采集器。
以采集 http://vip.book.sina.com.cn/book/index_40931.html 为例。
一、首先简单说一下制作采集器的基本原理和思路
1、确定采集页面到 “列表页面链接” 。
2、确定在这些页面要采集的内容区域,也就是 “列表区域识别规则” 。
3、确定要采集的文章链接,也就是 “文章链接 url 识别规则” 。
4、现在真正您需要采集的范围,就是 “文章标题识别规则” 和 “文章内容识别规则” 。
5、以上 4 个步骤已经确定了采集的范围,如果您需要过滤标题和内容,请根据您的要求设置 “过滤规则” 。
以上几个步骤确定范围都是通过查看页面源码,进行设置的,截取的方法需要一些经验,建议多点右边的 “测试” 看看是否成功。
二、接下来介绍采集器的基本原理和步骤
1、进入后台 => 采集管理 => 添加新机器人,如下图所示:
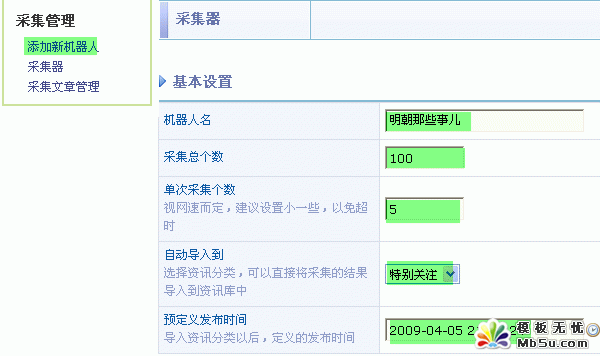
1)填写基本设置
“单次采集个数”尽量设置较小的数字,以免超时。
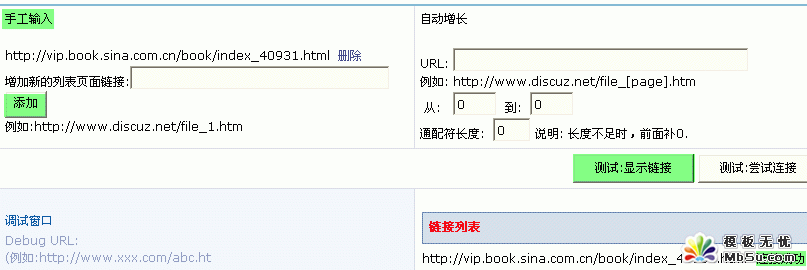
2)采集页面的 url 地址设置
采集页面的 url 地址有两种设置方法:手动输入和自动增长。手动输入需要您自己将所需采集的地址逐行输入。自动增长只需填入采集页面的地址和页面页码。用 [page] 代替分页变量。以手动输入为例,如下图所示:
3)采集页面编码
如果采集的页面和网站的不一样,需要填写下编码,你只需要点击【程序辅助识别】,把识别出来的填写到下图位置。如下图所示:

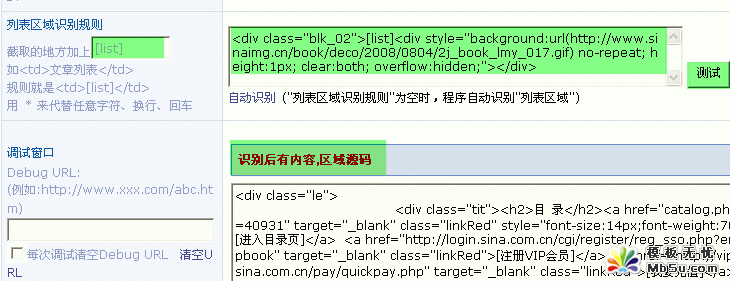
4)列表区域识别规则
在你要采集的页面中点击鼠标右键 => 查看源代码 => 找到文章链接URL区域。
文章链接 URL 区域 用 [list] 表示
左边 div 或者其他标签一定要选好,这里一定要注意,文章链接 URL 区域一定要在这个 div 内,而且是最近的,独一无二的。
建议大家用 Dreamweaver 工具查看
右边是接着左边的 div 结束后的标签,比如:
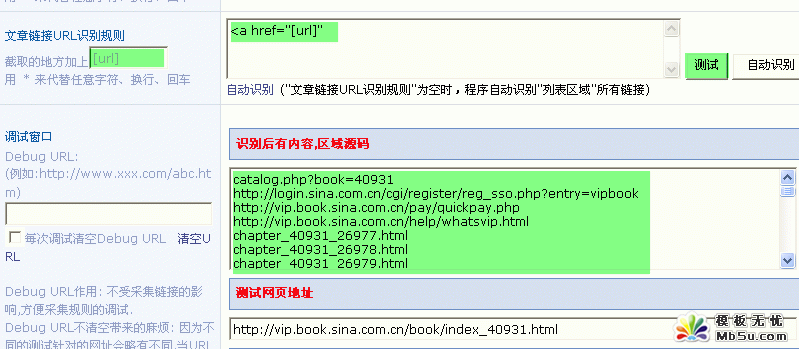
5)文章链接 URL 识别规则
现在需要的连接,如下图所示:

链接地址用 [url] 表示,比如:
添加文章链接 URL 规则后,发现有些链接是不需要的,所以需要使用“文章链接URL剔除规则”,如下图所示:
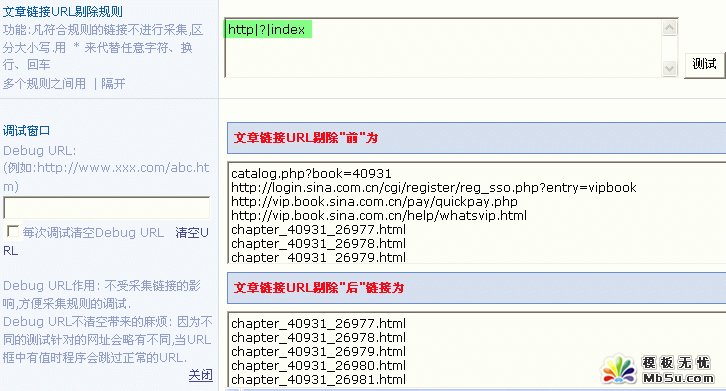
6)文章链接 URL 剔除规则
剔除规则如果有多个选择,请用 | 隔开,比如:
如下图所示:
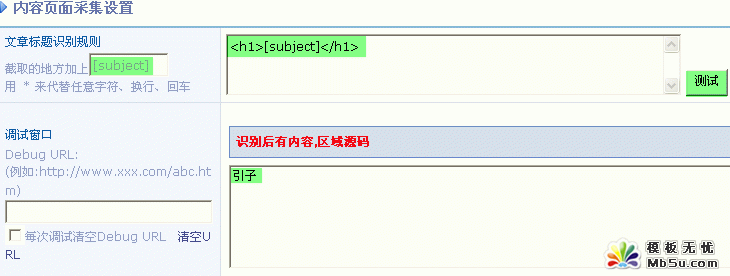
7)文章标题识别规则
点一个文章链接 => 在新打开的页面中点击鼠标右键 => 查看源代码 => 找到这篇文章的标题左右最近的标签
标题用 [subject] 表示,比如:
如下图所示:
8)文章内容识别规则
点一个文章链接 => 在新打开的页面中点击鼠标右键 => 查看源代码 => 找到这篇文章的内容左右最近的标签
内容用 [message] 表示,比如:
如下图所示:

2、这样采集规则就写好了,点击提交保存。页面跳转后,点击开始采集,如下图所示:

3、采集的过程,如下图所示:

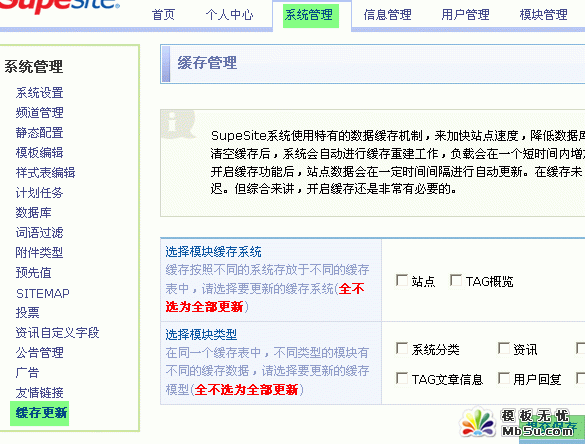
4、采集完毕之后,还需要更新下缓存,如下图所示:
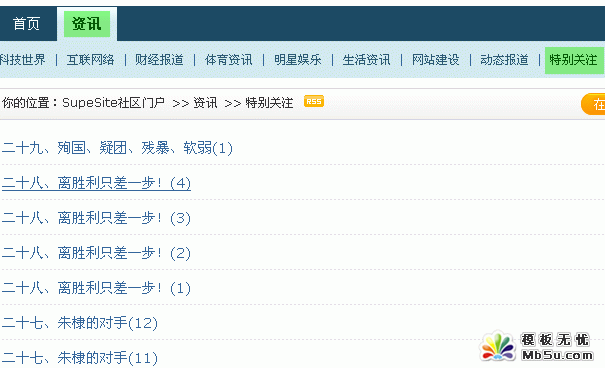
5、如果您的采集规则正确,打开首页就可以看到你刚刚采集到的内容,如下图所示:
查看更多 supesite教程 supesite模板
- SupeSite默认焦点轮转图简单美化方法
- SupeSite7.5 让资讯发布日期更加个性化
- SupeSite7.5 让会员中心拥有不同的title和提示信息
- SupeSite7.5 benbaHTML生成方案第一版
- SupeSite7.5发布评论后直接跳转回到文章页面的完美方法
- SupSite7.5单个页面频道编辑后无法访问
- SupSite7.5登陆后台先验证权限问题解决方案
- SupSite模型无权限评论修改方案
- SupSite模板里经常用到以下几个标签的说明
- SupSite页面文件与模块关系说明
- 升级SupeSite7.5出现Errno.: 1054的解决方法
- SupeSite7.5 非gbk版本程序,在回复某帖子时回复被截断修改方案
- 相关链接:
- 教程说明:
SupeSite教程-SupeSite 7.0 采集管理-添加新机器人说明教程
 。
。