
 閼辨俺顔�
閼辨俺顔� AI鐏忓繗浠� 閼宠棄鍟撴导姘辨暰
AI鐏忓繗浠� 閼宠棄鍟撴导姘辨暰 閸╃喎鎮�
閸╃喎鎮�不用代码10分钟就能学会微博知乎豆瓣淘宝数据采集_网站推广教程
推荐:婚纱摄影行业网络营销推广方案
婚纱摄影行业做网络营销相对来说就比较常见了,现在也有许多商家都在投入这一块。那婚纱摄影行业网络营销应该怎么做才会有效果呢?婚纱摄影行业网络推广方法又有哪些呢?怎么依托于网络和新媒体渠道打开婚纱摄影市场?
今天就推荐一款Google研发的数据采集插件,这款插件可以自带cookies,自带反爬虫能力,非常容易上手,按照流程下来,基本上10分钟就能学会了。我平时也经常用它采集微博、知乎、豆瓣、58同城、大众点评、汽车之家等等网站的内容,非常方便。
Web scraper是google强大插件库中非常强大的一款数据采集插件,有强大的反爬虫能力,只需要在插件上简单地设置好,可以快速抓取知乎、简书、豆瓣、大众、58等大型、中型、小型的90%以上的网站,包括文字、图片、表格等内容,最后快速导出csv格式文件。Google官方对web scraper给出的说明是:
使用我们的扩展,您可以创建一个计划(sitemap),一个web站点应该如何遍历,以及应该提取什么。使用这些sitemaps,Web刮刀将相应地导航站点并提取所有数据。稍后可以将剪贴数据导出为CSV。
本系列是关于web scraper的系类介绍,将会完整介绍流程介绍,用知乎、简书等网站为例介绍如何采集文字、表格、多元素抓取、不规律分页抓取、二级页抓取、动态网站抓取,以及一些反爬虫技术等全部内容。
Ok,今天就介绍web scraper的安装以及完整的抓取流程。
一、web scraper的安装
Web scraper是google浏览器的拓展插件,只需要在google浏览器上安装就可以了,介绍2种安装方法:
1、打开google浏览器更多工具下的拓展程序——进入到chrome 网上应用点——搜索web scraper——然后点击安装就可以了,如下图所示。
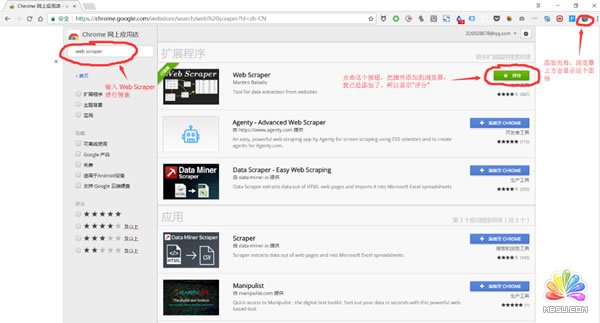
但是以上的安装方法需要翻墙到国外的网站上,所以需要用到vpn,如果有vpn的就可以用这种方法,如果没有就可以用下面的第二种方法:
2、通过链接:http://pan.baidu.com/s/1skXkVN3 密码:m672,下载web scraper安装程序。然后直接将安装程序拖入到chrome中的拓展程序就可以完成安装了。

完整完后就马上可以使用了。
二、以知乎为例介绍web scraper完整抓取流程
1、打开目标网站,这里以采集知乎第一大v张佳玮的关注对象为例,需要爬取的是关注对象的知乎名字、回答数量、发表文章数量、关注着数量。
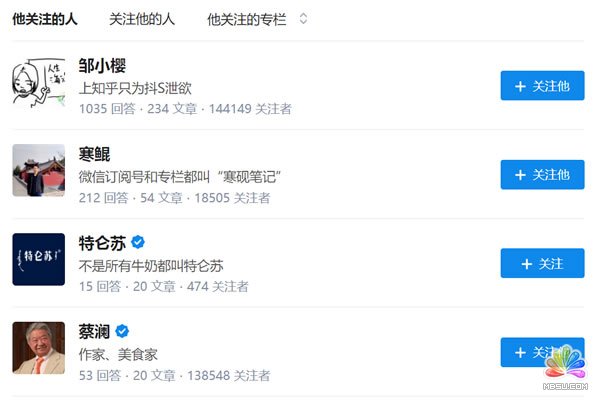
2、在网页上右击鼠标,选择检查选项,或者用快捷键 Ctrl + Shift + I / F12 都打开 Web Scraper。
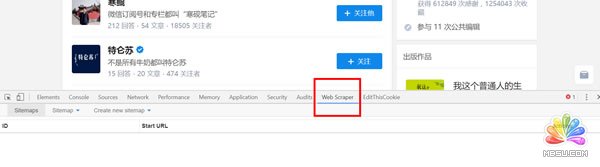
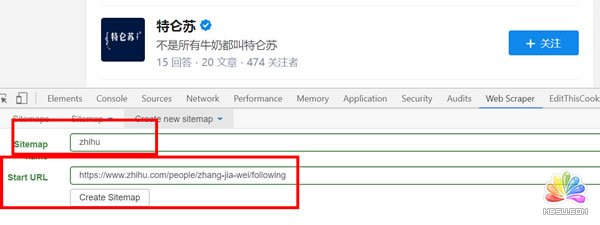
3、打开后点击create sitemap选择create sitemap创建一个站点地图。

点击create sitemap后就得到如图页面,需要填写sitemap name,就是站点名字,这点可以随便写,自己看得懂就好;还需要填写start url,就是要抓取页面的链接。填写完就点击create sitemap,就完成创建站点地图了。
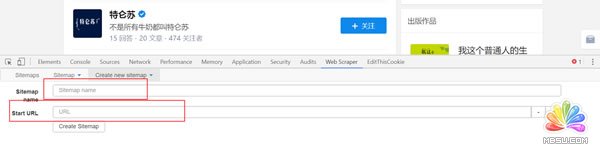
具体如下图:
4、设置一级选择器:选定采集范围
接下来就是重中之重了。这里先介绍一下web scraper的抓取逻辑:需要设置一个一级选择器(selector),设定需要抓取的范围;在一级选择器下建立一个二级选择器(selector),设置需要抓取的元素和内容。
以抓取张佳玮关注对象为例,我们的范围就是张佳玮关注的对象,那就需要为这个范围创建一个选择器;而张佳玮关注的对象的粉丝数、文章数量等内容就是二级选择器的内容。 具体步骤如下:
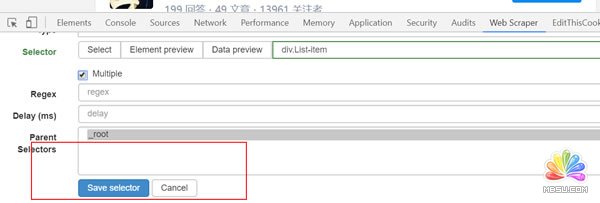
(1) Add new selector 创建一级选择器Selector:
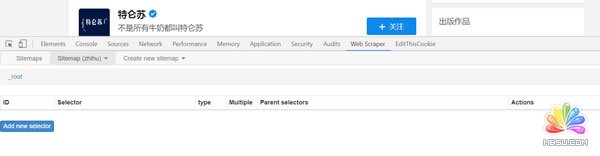
点击后就可以得到下图页面,所需要抓取的内容就在这个页面设置。
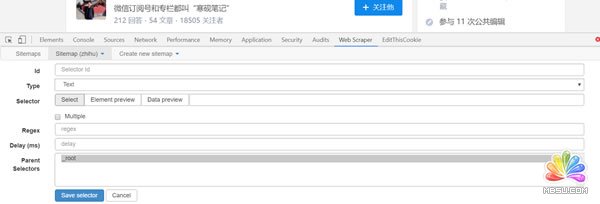
id:就是对这个选择器命名,同理,自己看得懂就好,这里就叫jiawei-scrap。
Type:就是要抓取的内容的类型,比如元素element/文本text/链接link/图片image/动态加载内Element Scroll Down等,这里是多个元素就选择element。
Selector:指的就是选择所要抓取的内容,点击select就可以在页面上选择内容,这个部分在下面具体介绍。
勾选Multiple:勾选 Multiple 前面的小框,因为要选的是多个元素而不是单个元素,当勾选的时候,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步就需要设置选择的内容了,点击select选项下的select 得到下图:

之后将鼠标移动到需要选择的内容上,这时候需要的内容就会变成绿色就表示选定了,这里需要提示一下,如果是所需要的内容是多元素的,就需要将元素都选择,例如下图所示,绿色就表示选择的内容在绿色范围内。

选择内容范围后,点击鼠标,选定的内容范围就会变成如下图的红色:
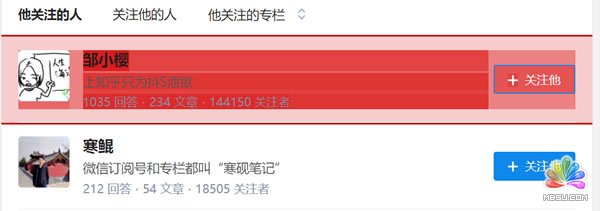
当一个内容变红后,我们就可以选择接下来的第二个内容,点击后,web scraper就会自动识别你所要的内容,具有相同元素的内容就都会变成红色的。如下图所示:
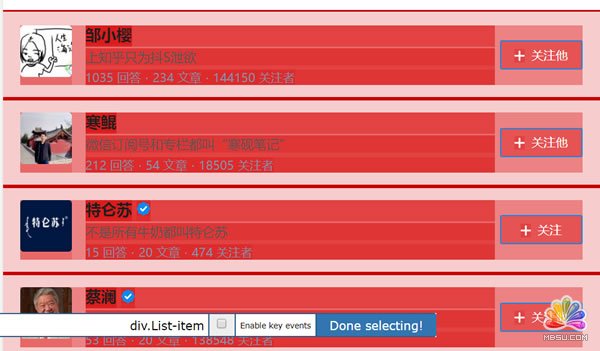
检查这个页面我们需要的内容全部变成红色之后,就可以点击 Done selecting选项了,就可以得到如下图所示:
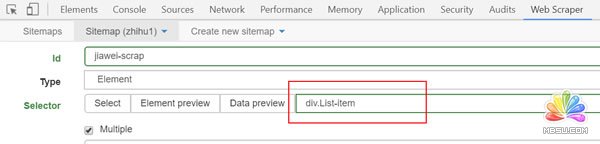
点击save selector,保存设置。到这里后,一级选择器就创建完成了。
5、设置二级选择器:选择需要采集的元素内容。
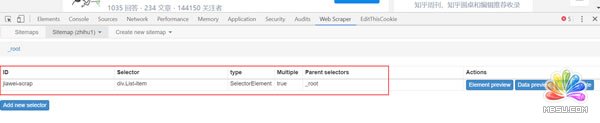
(1)点击下图中红框内容,就进入一级选择器jiawei-scrap下:
(2)点击add new selector创建二级选择器,来选择具体内容。
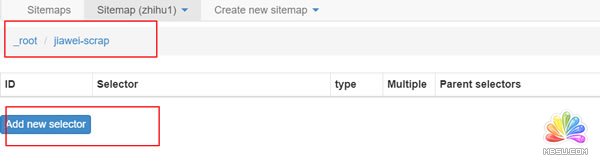
得到下图,这跟一级选择器的内容是相同的,但是设置是有区别的。

id:代表抓取的是哪个字段,可以取该字段的英文,比如要选「作者」,就写「writer」;
Type:这里选Text选项,因为要抓取的是文本内容;
Multiple:不要勾选 Multiple 前面的小框,因为在这里要抓取的是单个元素;
保留设置:其余未提及部分保留默认设置。
(3)点击select选项后,将鼠标移到具体的元素上,元素就会变成黄色,如下图所示:
在具体元素上点击后,元素就会变成红色的,就代表选定该内容了。
(4)点击Done selecting后完成选择,再点击save selector后就可以完成关注对象知乎名字的选取了。

重复以上操作,直到选完你想爬的字段。
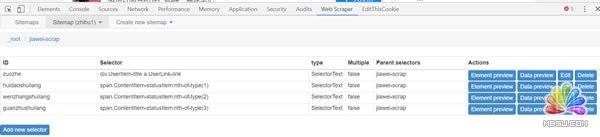
(5)点击红框部分可以看到采集的内容。
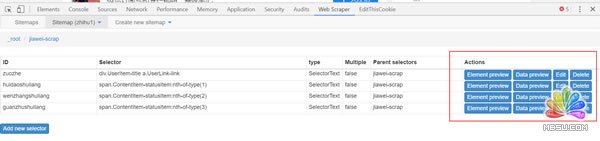
Data preview可以看到采集内容,edit可以对设置的内容做修改。
6、爬取数据
(1)只需要设置完所有的 Selector,就可以开始爬数据了,点击 Scrape map,
选泽scrape;:
(2)点击后就会跳到时间设置页面,如下图,由于采集的数量不大,保存默认就可以,点击 start scraping,就会跳出一个窗口,就开始正式采集了。
(3)稍等一会就可以得到采集效果,如下图:
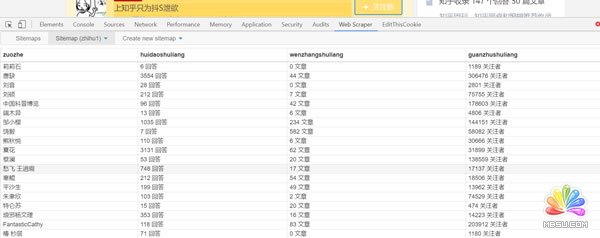
(4)选择sitemap下的export data as csv选项就可以将采集的结果以表格的形式导出。
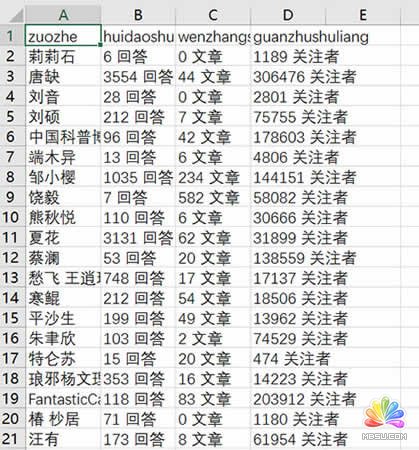
表格效果:
以上就是以知乎为例介绍基本的采集步骤和设置,看着虽然细节繁多,但是仔细算下来真没多少步骤,基本上10分钟就能够完全掌握采集的流程;无论是什么类型的网站,设置的基本流程都是大致一样的,有兴趣可以认真深入研究。
作者:白面书生 微信:zds369466004
原文地址:http://lusongsong.com/reed/9885.html
来源:卢松松博客,欢迎分享,(QQ/微信:13340454)
分享:活动运营,让用户为你疯狂打Call
早期的互联网行业,都是用不断砸钱的方式做活动运营,那是不是说参加我们活动的用户是唯利是图?其实我们每个人都是用户,大家想一下,我们选择一款产品,真的是贪图那点利益吗。不然,活动运营其实是一种感觉。
 评论加载中....
评论加载中....- 相关链接:
- 教程说明:
网站推广教程-不用代码10分钟就能学会微博知乎豆瓣淘宝数据采集
 。
。